TL;DR #
Running AI models locally is easier than ever with Ollama and Alpaca.
Ollama lets you run Large Language Models (LLMs) like LLaMA and DeepSeek on your device, while Alpaca provides a user-friendly GUI to manage and interact with these models seamlessly.
Introduction #
Ollama #
Ollama is a platform for running artificial intelligence (AI) models locally on your device. Ollama is designed to simplify the process of running Large Language Models (LLMs).
LLM (Large Language Model) is a type of AI model trained on vast amounts of text data to understand and generate natural language.
There are many Models you can try, such as LLaMA, Gemma, and DeepSeek, directly on your computer or personal server.
Alpaca #
Alpaca is an Ollama client (GUI) that makes it easier to run Ollama models.
Getting started is simple and hassle-free. Just install Alpaca, choose and download the AI model, and you’re ready to go!
Prerequisites #
Before you begin, make sure your system meets the following requirements:
Install Alpaca #
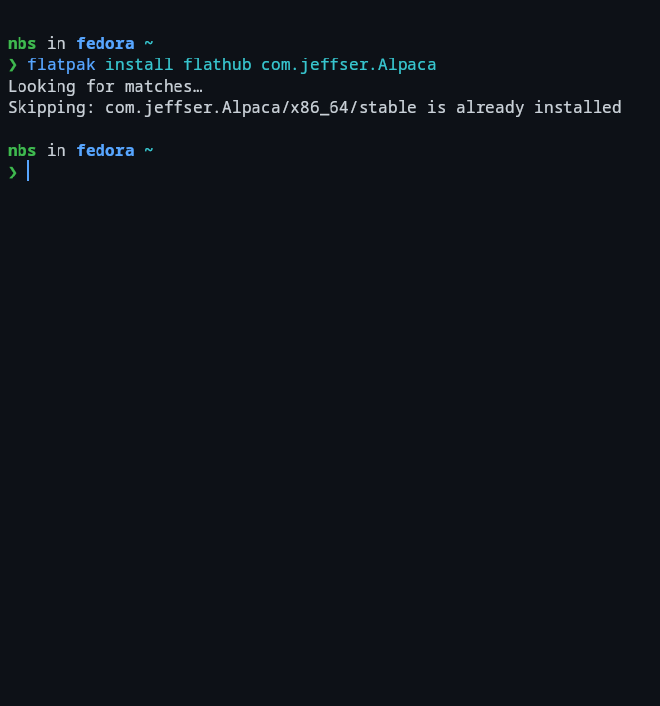
Install Alpaca via Flathub:
flatpak install flathub com.jeffser.Alpaca
Download an LLM #
You should have at least 8 GB of RAM available to run 7B models, 16 GB for 13B models, and 32 GB for 33B models.
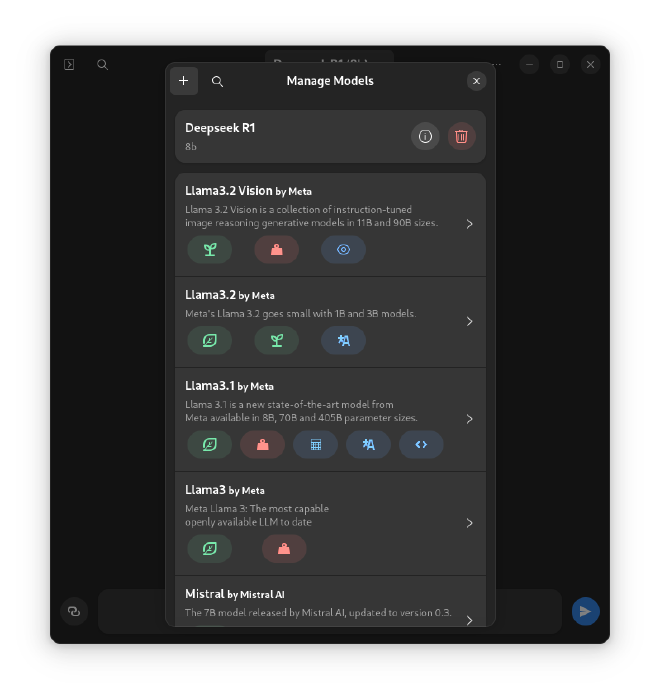
- Select “Manage Models”
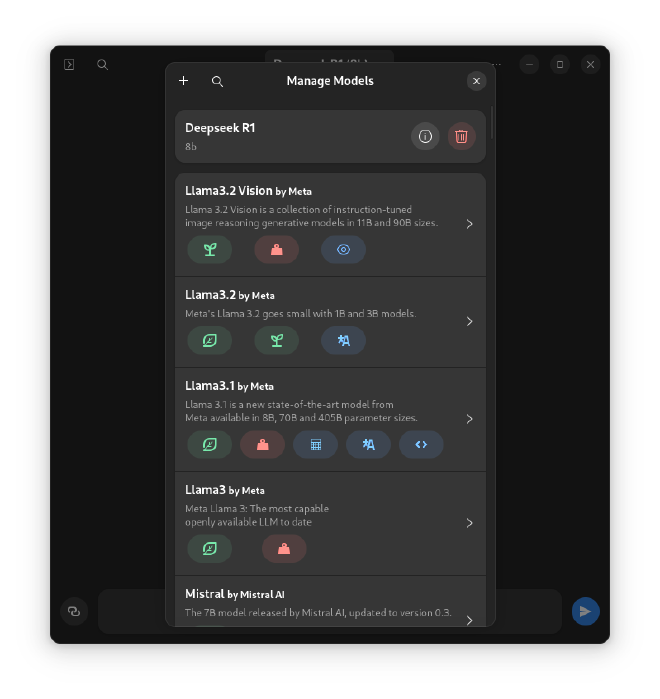
- Search for the model by name
- If the model is not displayed, click the plus button and “From Name” -> enter the model name and accept. You can find models on Ollama.
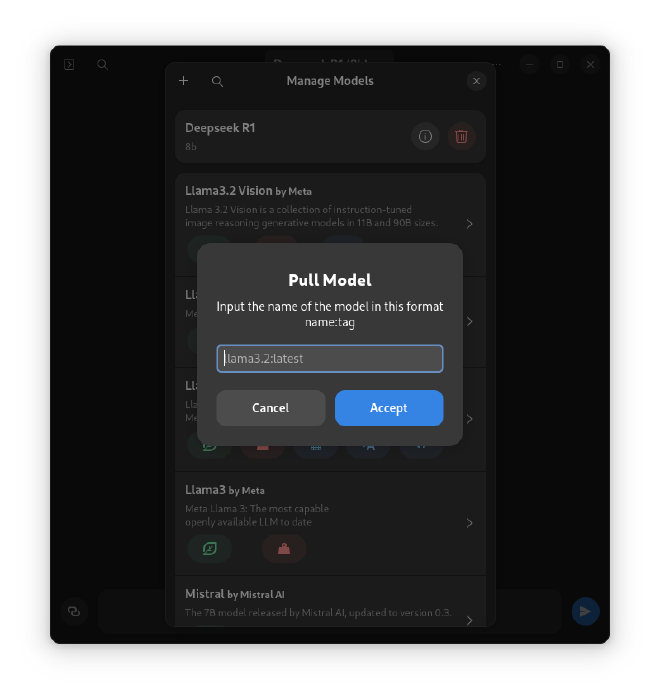
- Enter the model name and tags. For example: deepseek-r1:latest
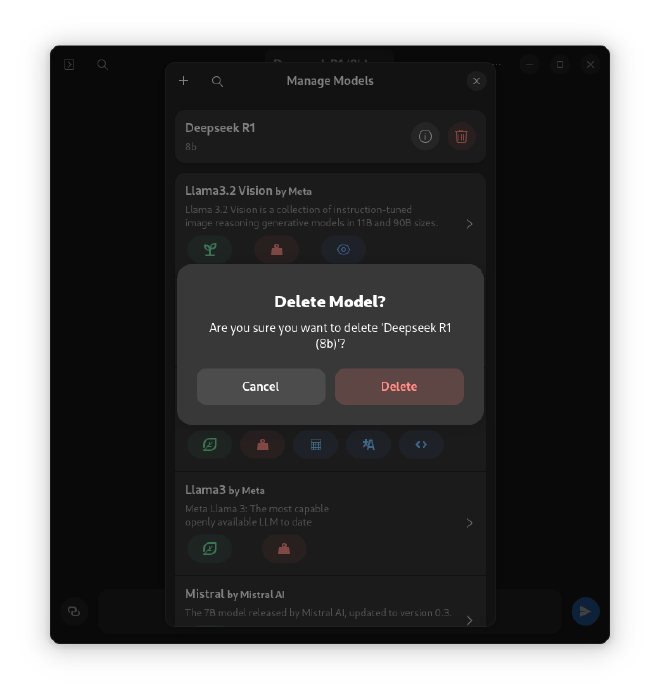
- If you want to remove a model, go to “Manage Models” and select “Remove.”
- Your local AI is now ready to use!
Using Your Local AI #
You’re all set! Now you can begin using your AI model locally. Simply try a prompt or enter your custom prompts to interact with your local AI.
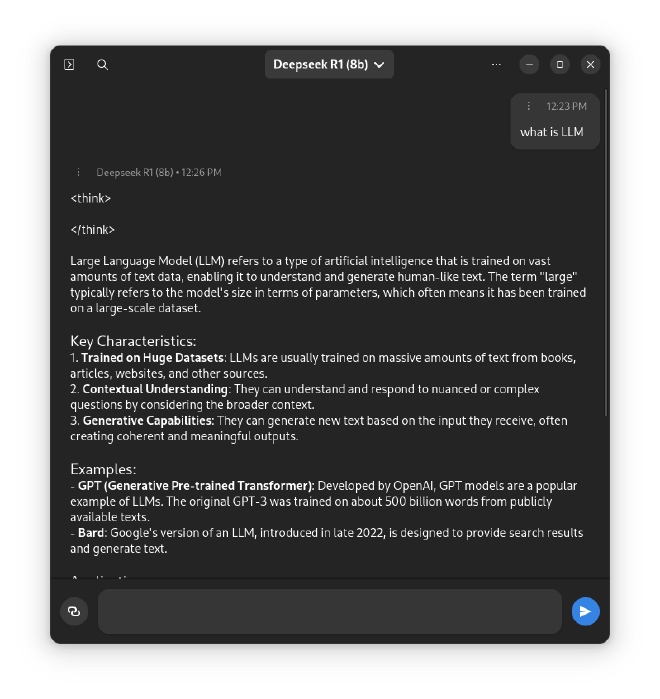
With Alpaca and Ollama, you can harness the power of advanced language models easily, all locally on your device.
Notes #
-
Device Requirements: Larger models (e.g., 13B, 33B) need more powerful devices (higher RAM, faster CPU/GPU). Ensure your device meets the recommended specs for optimal performance.
-
Prompt Speed: The model’s response time depends on its size and your device’s capabilities. Larger models take longer to generate responses.
-
Model Sizes: Smaller models (e.g., 1B) are faster and less resource-intensive, while larger models (e.g., 33B) offer more accurate results but require more resources.
Youtube Demo #
…